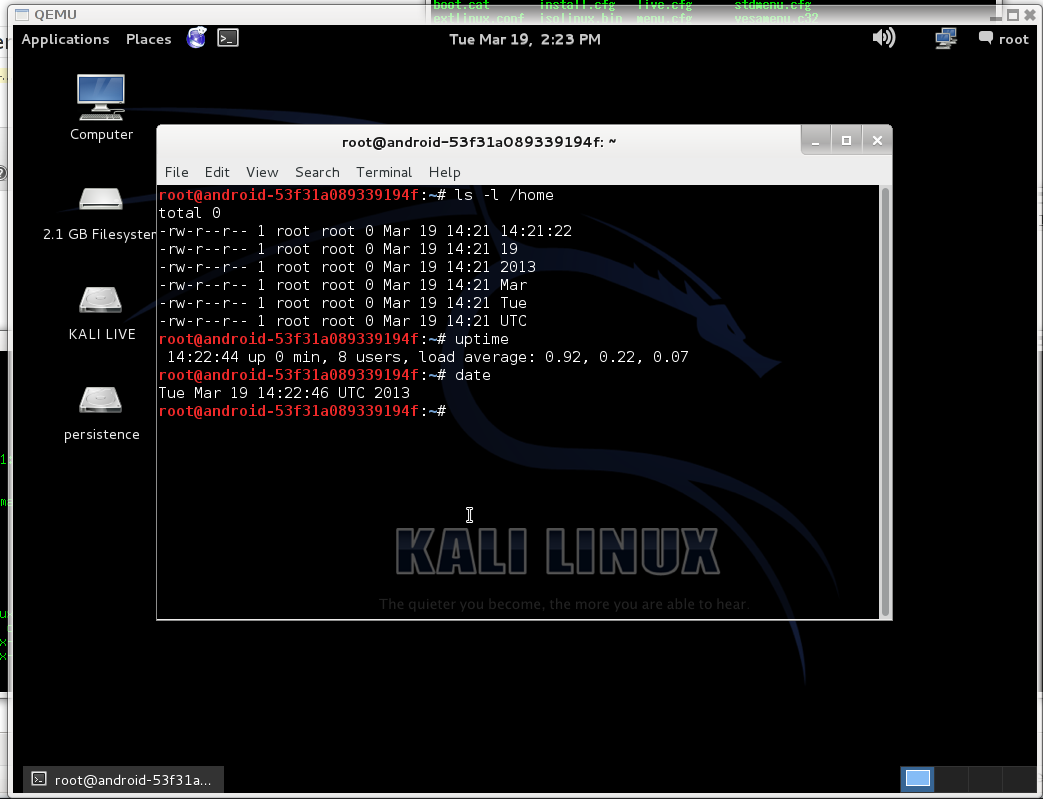
Few days ago i wanted to make liveusb with kali linux (i had backtrack before). I used this guide to install kali, but i observed, that persistence partition does not work. There is partitions on my usb drive:
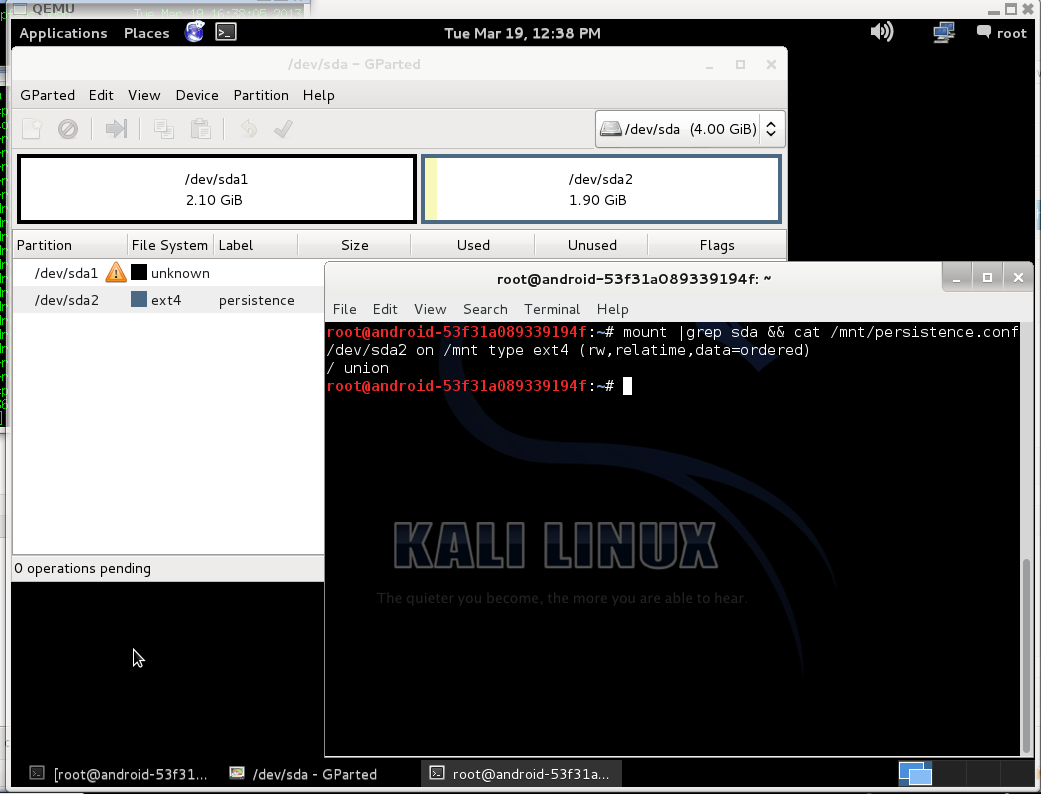
When init script found persistent partition and tried to mount their return error “mount: mounting /dev/sdaX on /root/lib/live/mount/persistence/sdaX failed: Device or resource busy”.
I think this happened because official guide suggest to write iso9660 image on usb drive, and init script think that it is cd drive and mount whole usb device, not a partition where iso placed. This i found in boot.log:
There you can see, that after kali boot, usb drive (sda) still mounted, and i can not mount second partition:
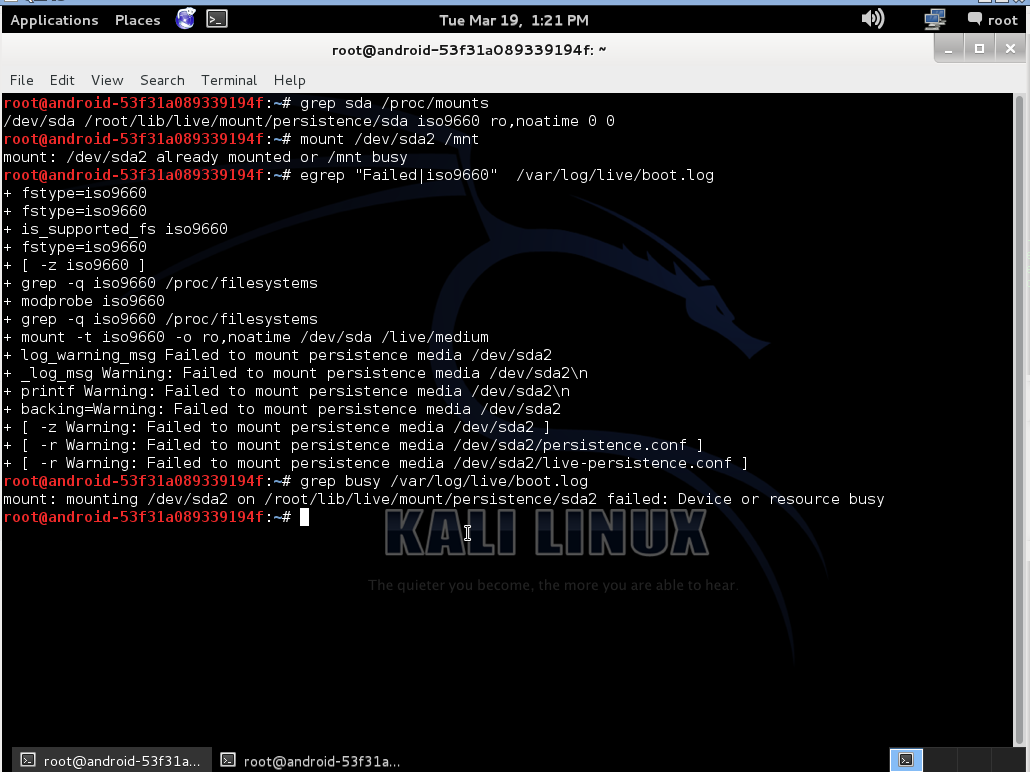
After that whole usb drive is busy. I attached boot.log to this post with enabled debug, may be it will help someone to fix that.
I decided to make bootable usb disk instead of flashing iso on it. For doing that i used extlinux and original kali iso file.
First i create 2 partitions on usb drive, one for kali and second for persistent files:
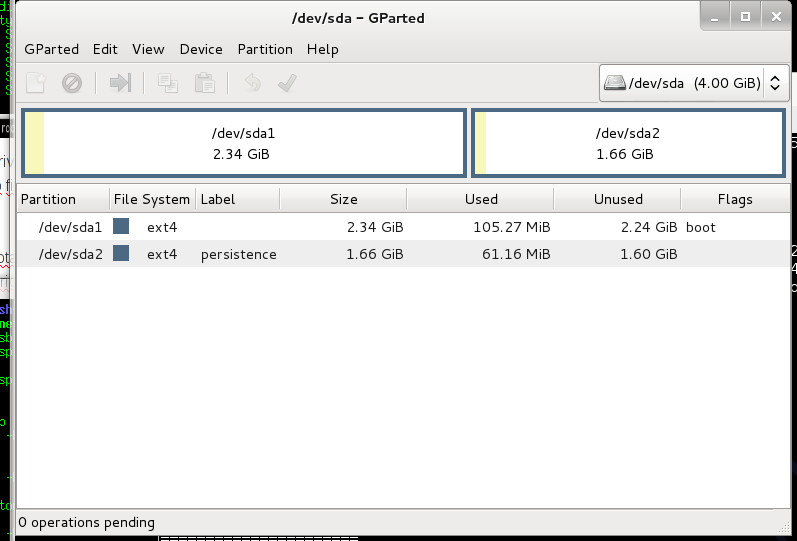
Do not forget to set bootable flag on first partition and correct label for persistent paririon.
After that, install mbr from extlinux:
$ dd if=/usr/lib/extlinux/mbr.bin of=/dev/sda
0+1 records in
0+1 records out
440 bytes (440 B) copied, 0.00126658 s, 347 kB/s |
$ dd if=/usr/lib/extlinux/mbr.bin of=/dev/sda
0+1 records in
0+1 records out
440 bytes (440 B) copied, 0.00126658 s, 347 kB/s
Copy kali linux on first partition:
$ mkdir /mnt/sr0 /mnt/kali
$ mount /dev/sr0 /mnt/sr0/
mount: block device /dev/sr0 is write-protected, mounting read-only
$ mount /dev/sda1 /mnt/kali/
$ rsync -a /mnt/sr0/* /mnt/kali |
$ mkdir /mnt/sr0 /mnt/kali
$ mount /dev/sr0 /mnt/sr0/
mount: block device /dev/sr0 is write-protected, mounting read-only
$ mount /dev/sda1 /mnt/kali/
$ rsync -a /mnt/sr0/* /mnt/kali
Also i modify boot menu and add entry with persistence boot option at live.cfg:
label live-686-pae-persistence
menu label ^Live persistence (686-pae)
menu default
linux /live/vmlinuz
initrd /live/initrd.img
append boot=live noconfig=sudo username=root hostname=android-53f31a089339194f persistence |
label live-686-pae-persistence
menu label ^Live persistence (686-pae)
menu default
linux /live/vmlinuz
initrd /live/initrd.img
append boot=live noconfig=sudo username=root hostname=android-53f31a089339194f persistence
After that you need to rename isolinux.cfg to extlinux.conf and install extlinux:
$ cp /mnt/kali/isolinux/isolinux.cfg /mnt/kali/isolinux/extlinux.conf
$ extlinux --install /mnt/kali/isolinux/
/mnt/kali/isolinux/ is device /dev/sda1 |
$ cp /mnt/kali/isolinux/isolinux.cfg /mnt/kali/isolinux/extlinux.conf
$ extlinux --install /mnt/kali/isolinux/
/mnt/kali/isolinux/ is device /dev/sda1
Mount persistence partition and create config:
$ mkdir /mnt/persist
$ mount /dev/sda2 /mnt/persist/
$ echo "/ union" > /mnt/persist/persistence.conf |
$ mkdir /mnt/persist
$ mount /dev/sda2 /mnt/persist/
$ echo "/ union" > /mnt/persist/persistence.conf
After that you can reboot and check, that persistent partition work.